Hente ut data, sammenfatte og gradere
Publisert
Datauthenting vil si å hente ut relevant informasjon fra de inkluderte studiene eller oversiktene.
Om denne fasen
|
Inn til denne fasen |
Liste med inkluderte oversikter/enkeltstudier og deres metodiske kvalitet/risiko for systematiske skjevheter. |
|
Beskrivelse |
Hente ut data og sammenfatte resultatene fra de inkluderte studiene for å gi en narrativ eller statistisk sammenfatning av effekt og sikkerhet. Vise tilliten til resultatene (med GRADE). |
|
Hvorfor denne fasen? |
Gi en så presis som mulig sammenfatning av effekt og sikkerhet for viktige utfall fra de relevante studiene. |
|
Ansvar |
Prosjektleder. |
|
Oppgaver |
Ekstrahere (hente ut) data fra studiene. Foreta en vurdering av dataene på tvers av studiene. Vurdere grunnlag for kvantitativ (statistisk) sammenfatning. Gradere tilliten til resultatene for viktige utfall. |
|
Verktøy |
Denne håndboka, GRADE handbook, Cochrane Handbook. |
|
Leveranse |
Tekst, tabeller, eventuelt metaanalyse. |
Uthenting av data
Datauthenting vil si å hente ut relevant informasjon fra de inkluderte studiene eller oversiktene. Prosjektplanen spesifiserer hvilke data vi skal hente ut fra den enkelte studien eller oversikten. Det kan være nyttig å bruke et dataekstraksjonsskjema med detaljene som er vist i boksen nedenfor. Én person henter ut data og dette sjekkes så av en annen. Vi løser uenighet ved diskusjon eller ved å konsultere en tredje person.
Viktige elementer i et skjema for datauthenting fra effektstudier
Generelt
- Tittel, forfattere, detaljer om publikasjonen
- Plass til å notere spørsmål og annet det er viktig å huske på
- Endelig verifisering av at publikasjonen oppfyller inklusjonskriteriene og bør inkluderes
Kjennetegn ved primærstudier
- Populasjonen (antall inkludert i hver gruppe, alder, kjønn, diagnose, alvorlighetsgrad, komorbiditet, ev. andre relevante karakteristika)
- Hvor og når studien ble utført (årstall, land, i eller utenfor sykehus osv.)
- Intervensjonen(e)
- Sammenlikning(er)
- Finansieringskilde(r) av studien
Kjennetegn ved systematiske oversikter
- Kvaliteten på den systematiske oversikten
- Dato for litteratursøket
- Inkluderte sammenlikninger
Utfall og resultater
- Utfall (som spesifisert i prosjektplanen, eventuelt skille mellom primære og sekundære utfall)
- Ulike typer utfall/utfallsmål
- Diskrete data: Antall hendelser og antall personer i gruppene (risk ratio/relativ risiko (RR), odds ratio (OR)), p-verdier og konfidensintervall (KI)
- Kontinuerlige data: Gjennomsnitt, standardavvik, andre statistiske mål
- Data som er målt over tid («overlevelsesdata»)
- Oppfølgingstid og målemetode
- Justerte data der de er tilgjengelige (og informasjon om hvilke faktorer det er justert for)
- Frafall
- Hvordan manglende data er håndtert
Bruk av data fra primærstudier om effekt av tiltak
Når vi bruker data fra primærstudier, må vi vurdere og sammenfatte resultatene for hver sammenlikning. Dersom den systematiske oversikten skal inkludere flere studiedesign, bør disse sorteres hver for seg. Deretter sammenfattes resultatene for hvert av de relevante utfallsmålene. Dette kan gjøres ved en deskriptiv, ikke-kvantitativ syntese, eller når det ligger til rette for det, en kvantitativ syntese ved bruk av statistiske metoder (metaanalyse). I begge tilfeller er det viktig å vurdere hvorvidt effektene er konsistente på tvers av alle de inkluderte studiene, både de som kan inngå i en metaanalyse og de som eventuelt ikke har data som kan benyttes i metaanalysen.
Dersom resultatene fra de ulike studiene ikke er konsistente, må vi vurdere studiene for å finne mulige årsaker til dette. Vi presenterer resultatene i balansediagram (forest plot) og GRADE-tabeller (se senere i kapittelet).
Beskrivelse av studiene og resultatene
De fleste typer oversikter presenterer informasjon om de inkluderte studiene i en tabell som viser studiekarakteristika og en tabell som viser risiko for systematiske skjevheter. I tillegg oppsummeres og beskrives resultatene fra studiene i tekst.
Narrativ syntese / beskrivende syntese
Dersom studiene er for ulike (klinisk eller metodisk heterogene) til at vi kan sammenfatte resultatene i en metaanalyse, bør vi beskrive dem hver for seg og sammenfatte dem ved en «beskrivende» syntese. Vi bør unngå å oppsummere resultatene ved å telle antall studier som viser en effekt og antall som ikke gjør det for å gi en samlet konklusjon (såkalt «vote counting»), da dette ofte blir misvisende fordi studiene kan ha ulik kvalitet og størrelse.
Målet med en slik syntese er å beskrive de samlede resultatene, retningen og størrelsen på effektestimatene for de viktigste utfallene. Dette gjør vi ved å vurdere hvor konsistente og sikre resultatene er i og på tvers av studiene. Prosessen forutsetter subjektive vurderinger, og det er derfor viktig å ha klare kriterier for hvilke elementer vi skal legge vekt på. «Synthesis without meta-analysis - SWiM» er en retningslinje for rapportering av narrative/beskrivende synteser (1).
Vi presenterer resultatene for de effektmålene/utfallsmålene som er beskrevet i prosjektplanen. Vi bør gjøre rede for hvor mange studier av de totalt inkluderte for en sammenlikning som har data på effekt og sikkerhet.
Vi kan måle og presentere effektestimater på mange ulike måter og med en rekke metoder. Vi bør benytte metoder som er validerte, også for den populasjonen vianvender dem på.
Vi skal beskrive hvilke effektestimater vi vektlegger i prosjektplanen. Vi presenterer også konfidensintervaller til resultatene så sant det er mulig.
Dikotome utfall
Dikotome utfall brukes når vi klart kan si at en hendelse har skjedd eller ikke (for eksempel død/ikke død; syk/ikke syk). Effektestimater presenteres som absolutte verdier (antall hendelser, absolutt risikoforskjell eller eventuelt number-needed-to-treat (NNT)), og som relative verdier (risk ratio/relativ risiko, odds ratio, relativ risikoreduksjon).
Kontinuerlige data
Kontinuerlige data brukes når effektestimatet måles på en skala. Effektestimatet kan presenteres som absolutte eller relative gjennomsnittlige forskjeller (mean difference – MD) mellom gruppene. Ofte vil en erfare at studier har rapportert samme utfall, men benytter ulike skalaer for å måle det. Da er en mye brukt metode å beregne standardisert gjennomsnittlig forskjell (standardized mean difference - SMD). Det kan være nyttig å beregne det samlede effektestimatet tilbake til en av skalaene for å vise hva resultatene kan bety i praksis.
Tidskurver (overlevelseskurver)
Tidskurver brukes for å analysere tid til en hendelse, der ikke alle de inkluderte nødvendigvis opplever hendelsen, og der risikoen for å oppleve hendelsen avhenger av tiden. Et eksempel er overlevelseskurver. For overlevelsesdata rapporterer vi resultater i hazard ratio (veid gjennomsnitt av relativ risiko i løpet av en oppfølgingsperiode), med konfidensintervall.
Det står mer om ulike effektestimater i Cochrane Handbook, kapittel 6 (2).
Metaanalyse
Metaanalyse er en statistisk metode for å oppsummere resultatene av flere enkeltstudier, der man gir store studier med flere hendelser større vekt enn små studier.
Ofte vil ulike studier presentere data på forskjellige måter; det kan være ulike skalaer, ulike tidspunkt for måling eller ulike terskler med mer. Det kan også være en rekke andre forskjeller mellom studiene (populasjon, type intervensjon eller sammenlikning). Derfor er det nødvendig å vurdere hvilke data som er like nok til at vi kan kategorisere og beskrive dem sammen, og hvilke data som kan inngå i en metaanalyse. Det er som regel hensiktsmessig å få råd eller hjelp av statistiker når vi skal utføre metaanalyser.
Metaanalyse utarbeides dersom det er beskrevet i prosjektplanen og det er et tilstrekkelig homogent datagrunnlag. En slik syntese forutsetter ikke bare at man i primærstudiene har undersøkt samme problemstilling på sammenliknbare utvalg av deltakere, men også at man har målt det samme med sammenliknbar metode. Når vi gjør metaanalyser, følger vi hovedsakelig metodene som er beskrevet i Cochrane Handbook, kapittel 10 (2).
Det er tre spørsmål som vi må avklare:
- Hvilke sammenlikninger skal vi gjøre?
- Hvilke utfallsmål skal vi bruke?
- Hvilke effektmål skal vi bruke?
Disse forholdene bør vi ha tenkt over og beskrevet i prosjektplanen. Det kan imidlertid være nødvendig å modifisere planen når det blir klart hva slags data de enkelte studiene rommer. Vi må dokumentere eventuelle modifiseringer av prosjektplanen.
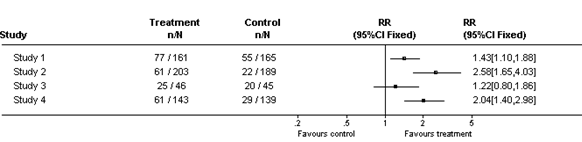
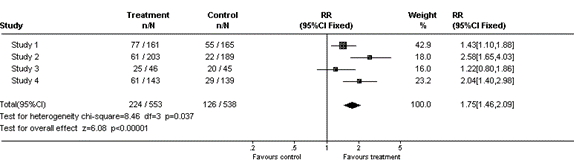
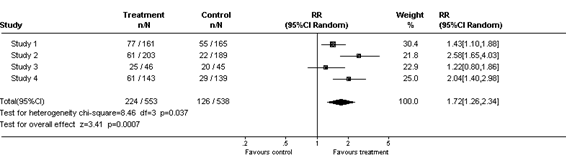
I metaanalysen tar vi effektestimatene fra hver enkelt studie. Dette vektes i analysen, som regel basert på hvor mange hendelser og deltakere hver studie hadde (studier med smalere konfidensintervall har gjerne større vekt), og et samlet effektestimat beregnes for hvert endepunkt. Det gjøres med dataprogrammer, som også beregner hvor presist estimatet er (dvs. etablerer et konfidensintervall). Resultatene presenteres i et såkalt balansediagram (forest plot) som vist nedenfor. Firkantene viser effektestimater fra de enkelte studiene, og de horisontale linjene viser konfidensintervallene. Størrelsen på firkantene indikerer vekten på studien. Diamanten nederst viser det samlede effektestimatet fra metaanalysen, og bredden av den viser konfidensintervallet. Den vertikale linjen er «linjen for ingen forskjell» («the line of no effect»).
Fordi studiene som kombineres er forskjellige, vil det alltid være noe variasjon eller heterogenitet mellom dem. Heterogenitet kan være klinisk (forskjeller mellom deltakerne, tiltakene eller utfallene), metodisk (forskjell i studiedesign eller risiko for systematiske skjevheter (bias) mellom studiene) eller tilfeldig. Effektestimatene fra studiene kan kombineres med en fiksert (fixed) effektmodell der det antas at de enkelte studiene kan sees på som deler av én stor studie, eller en tilfeldig (random) effektmodell der man åpner for at det kan være systematiske forskjeller mellom enkeltstudiene. De fleste av våre sammenfatninger egner seg for tilfeldig effektmodell.
Nedenfor gir vi eksempler på tre ulike måter å sammenfatte data fra fire studier i en systematisk oversikt (forest plot):
a) Presented without metaanalysis:
b) Presented with metaanalysis (fixed effect model):
c) Presented with mata-analysis (random effects model):
Vurdering av tillit til resultatene
Når vi sitter med en eller flere relevante studier som har informasjon om en bestemt sammenlikning og et eller flere utfall (f.eks. om effekten av et bestemt tiltak mot smerte sammenliknet med et annet tiltak eller ikke noe tiltak), bør vi vurdere hvilken tillit vi har til resultatene. Er det grunn til å tro at dette samlet sett er et robust effektestimat, som neppe vil bli påvirket selv om det kommer nye studier?
I område for helsetjenester i Folkehelseinstituttet bruker vi GRADE (Grading of Recommendations Assessment, Development and Evaluation) (3), som definerer tilliten til den samlede dokumentasjonen slik:
|
GRADE |
Definisjon |
Symbol |
|
Høy tillit |
Vi har stor tillit til at effektestimatet ligger nær den sanne effekten |
⨁⨁⨁⨁
|
|
Moderat tillit |
Vi har moderat tillit til effektestimatet: Det ligger sannsynligvis nær den sanne effekten, men det er også en mulighet for at den kan være forskjellig |
⨁⨁⨁◯
|
|
Lav tillit |
Vi har begrenset tillit til effektestimatet: Den sanne effekten kan være vesentlig ulik effektestimatet |
⨁⨁◯◯
|
|
Svært lav tillit |
Vi har svært liten tillit til at effektestimatet ligger nær den sanne effekten |
⨁◯◯◯
|
GRADE er en metode for å vurdere tilliten til dokumentasjonen og styrken på anbefalingene. Kunnskapsoppsummeringene våre gir ikke anbefalinger og vi bruker derfor bare GRADE til å vurdere tilliten til dokumentasjonen for hvert utfall. GRADE kjennetegnes ved transparens. Vi viser fram vurderingene som vi har gjort i fotnoter til GRADE-tabellene (3).
Utgangspunktet for bruk av GRADE er en systematisk oversikt av høy metodisk kvalitet over spørsmålet vi søker å besvare. Dette vil enten være oversikten vi er i ferd med å lage eller en oversikt laget av andre. Spørsmålet definerer hvilke virkemidler eller intervensjoner som sammenliknes (f.eks. massasje versus varmebehandling), hvilke mennesker intervensjonen skal testes på (f.eks. voksne med akutte korsryggsmerter) og hvilke utfall som er av interesse (f.eks. positive utfall som mindre smerte, og negative utfall som bivirkninger).
Med GRADE-tilnærmingen utvikler vi en evidensprofil for det spesifikke spørsmålet som vi skal belyse. En GRADE-profil viser tydelig hvilke vurderinger som vi har gjort ved graderingen av vår tillit til dokumentasjonen, for hvert utfall som er definert. I tillegg presenterer vi en tabell som oppsummerer og viser tilliten til resultatene («Summary of Findings table»).
Kriterier for vurdering av tillit med GRADE
Studiedesign er utgangspunkt for vurderingen av utfallene. Vi deler i to hovedkategorier: randomiserte studier og ikke randomiserte studier eller observasjonsstudier. Randomiserte studier starter på høy tillit, og observasjonsstudier starter på lav tillit. Vi vurderer åtte kriterier: fem som kan resultere i nedgradering, og tre som kan føre til oppgradering.
Studiekvalitet/ risiko for systematiske skjevheter handler om planlegging og utføring av studien. For hvert av utfallene må vi vurdere risiko for systematiske skjevheter. Vi noterer hvorfor og hvor mye tilliten eventuelt blir nedgradert.
Konsistens eller samsvar mellom studiene handler om hvor like effektestimatene for utfallet er mellom de forskjellige studiene. Heterogenitet (manglende samsvar) kan vise seg ved at resultatene fra forskjellige studier peker i forskjellige retninger, eller at det er stor forskjell i effektstørrelsen. Er det uforklarlig heterogenitet i resultatene, nedgraderer vi vår tillit til dette utfallet. Hvis heterogeniteten kan forklares med forskjeller i de ulike elementene i PICO (pasientkarakteristika, intervensjon/tiltak eller sammenlikning, utfallene) eller ulik design/kvalitet på studiene, bør vi vurdere om vi bør lage egne evidensprofiler for hver av disse gruppene.
Direkthet handler om hvor like studiedeltakere, intervensjoner, sammenlikninger og utfallsmål i de inkluderte studiene er når det gjelder spørsmålet som stilles.
- Har vi grunn til å tro at studiedeltakerne ikke er representative for pasientene dokumentasjonen skal brukes på, for eksempel hvis de er sykere eller eldre, kan vi nedgradere vår tillit for dette utfallet.
- Hvis intervensjonen er vesentlig forskjellig fra den som spørsmålet egentlig beskriver, for eksempel med hensyn til type legemiddel, dosering eller behandlingsintensitet, nedgraderer vi for dette utfallet.
- Er utfallet viktig, riktig målt og direkte relevant til spørsmålet? Bruk av surrogatutfall kan gi misvisende resultater.
- En annen form for mangel på direkthet er når vi mangler direkte sammenlikning mellom de to intervensjonene som vurderes, og vi må ty til en indirekte sammenlikning: for eksempel om vi vil sammenlikne effekten av A og B, men bare finner A sammenliknet med placebo og B sammenliknet med placebo.
Presisjon handler om hvor presise resultatene er, hvor mye data vi har og hvor stor usikkerheten i resultatene er. Hvis estimatet kun inkluderer noen få hendelser, og estimatet dermed har brede konfidensintervaller, kan vi vurdere å nedgradere vår tillit til dette utfallet.
Rapporteringsskjevheter handler både om publiseringsskjevheter og skjevheter i hvilke utfall som rapporteres. Dersom vi har grunn til å tro at det foreligger rapporteringsskjevhet, nedgraderer vi for det aktuelle utfallet.
De tre kriteriene i GRADE-systemet for å oppgradere tilliten til dokumentasjonen gjelder kun der det er flere samsvarende observasjonsstudier som ikke er nedgradert:
- Sterke eller veldig sterke assosiasjoner/sammenhenger mellom intervensjon og utfall.
- Store eller veldig store dose–responseffekter (jo sterkere «dose» av intervensjonen, jo sterkere respons).
- Der alle sannsynlige forvekslingsfaktorer ville ha redusert effekten eller ville ha skapt en falsk effekt når resultatene antyder ingen effekt.
Av tabellen nedenfor framgår det hvordan vi bruker de aktuelle kriteriene til å vurdere tilliten til dokumentasjonen for viktige utfall i en systematisk oversikt (3).
|
Vår tillit til dokumentasjonen |
Studiedesign |
Nedgrader ved |
Oppgrader ved* |
|
Høy |
Randomiserte studier |
Begrensninger ved studiekvaliteten (risiko for systematiske skjevheter) -1 Alvorlig -2 Veldig alvorlig
Mangel på konsistens -1 Alvorlig -2 Veldig alvorlig
Mangel på direkthet -1 Alvorlig -2 Veldig alvorlig eller flere faktorer
Mangel på presisjon -1 Alvorlig -2 Veldig alvorlig
Rapporteringsskjevheter -1 Sannsynlig -2 Veldig sannsynlig |
Sterk sammenheng +1 Sterk +2 Veldig sterk
Dose-responseffekt +1 holdepunkter for dose-responseffekt
Forvekslingsfaktorer +1 Alle kjente forvekslingsfaktorer ville ha redusert effekten |
|
Middels |
|
||
|
Lav |
Observasjonsstudier/ ikke randomiserte effektstudier |
||
|
Svært lav |
|
*Forutsetter at det er flere samsvarende observasjonsstudier som ikke er nedgradert.
GRADE håndterer både randomiserte og ikke-randomiserte studiedesign. Der det dreier seg om et effektspørsmål og dokumentasjonen består av randomiserte studier, er dette i utgangspunktet et godt grunnlag for å trekke konklusjoner om effektestimater. Randomiserte studier starter på høy tillit. Dersom det imidlertid er svakheter i måten forsøkene ble utformet og gjennomført på (høy risiko for systematiske skjevheter), kan vurderingen bli nedjustert ett trinn, eller ved svært alvorlige svakheter justeres ned to trinn (til lav tillit). Hvis forsøkene i tillegg har relativt få observasjoner (lite data), kan kvaliteten nedgraderes ytterligere (til svært lav tillit).
I et annet tilfelle kan det for eksempel være et effektspørsmål som bare er bedømt ved hjelp av observasjonsstudier (f.eks. kohort- eller kasus-kontrollstudier). Da er faren for å feilbedømme effekten større enn ved randomiserte studier, og vi starter med lav tillit. Dersom det imidlertid er påvist en sterk sammenheng mellom intervensjon og utfall i godt utførte ikke randomiserte studier, kan tilliten til dokumentasjonen oppgraderes ett trinn. Hvis studiene i tillegg tyder på en klar sammenheng mellom dosering av intervensjonen og respons på utfallet, kan tilliten til dokumentasjonen oppgraderes enda ett trinn og alt i alt vurderes som høy.
GRADE-tilnærmingen er beskrevet og illustrert med eksempler i The GRADE Handbook.
Formuleringer i GRADE for å uttrykke resultater fra kunnskapsoppsummeringer om effekt
For å harmonisere og standardisere resultatformuleringene skal kunnskapsoppsummeringer og metodevurderinger i HTV benytte de norske oversettelsene av veiledningen fra GRADE working group i GRADE guidelines 26 (4).
| Informative formuleringer for å formidle resultater av kunnskapsoppsummeringer | |
|
Effektestimatets størrelse |
Formuleringer
|
|
HØY tillit til kunnskapsgrunnlaget |
|
|
Stor effekt |
X gir en stor reduksjon/økning i utfall |
|
Moderat effekt |
X reduserer/øker utfall X gir en reduksjon/økning i utfall |
|
Liten, men viktig effekt |
X reduserer/ øker utfall noe/litt X gir en liten/svak reduksjon/økning i utfall |
|
Liten og uvesentlig effekt eller ingen effekt |
X gir liten eller ingen forskjell i utfall X reduserer/øker ikke utfall X hverken bedrer eller forverrer utfall (ev: hverken reduserer eller øker) |
|
MODERAT tillit til kunnskapsgrunnlaget |
|
|
Stor effekt |
X gir trolig/sannsynligvis en stor reduksjon/økning i utfall |
|
Moderat effekt |
X reduserer/øker trolig/sannsynligvis utfall X gir trolig/sannsynligvis en reduksjon/økning i utfall |
|
Liten, men viktig effekt |
X reduserer/øker trolig/sannsynligvis utfall noe/litt X gir trolig/sannsynligvis en liten/svak reduksjon/økning i utfall |
|
Liten og uvesentlig effekt eller ingen effekt |
X gir trolig/sannsynligvis liten eller ingen forskjell i utfall X reduserer/øker trolig/sannsynligvis ikke utfall Trolig/Sannsynligvis gir X hverken reduksjon/økning eller [sett inn motstykke til reduksjon/økning] i utfall |
|
LAV tillit til kunnskapsgrunnlaget |
|
|
Stor effekt |
X kan muligens/kanskje gi en stor reduksjon/økning i utfall Kunnskapsgrunnlaget antyder at X kan gi en stor reduksjon/økning i utfall |
|
Moderat effekt |
X kan muligens/kanskje redusere/øke utfall Kunnskapsgrunnlaget antyder at X kan redusere/øke utfall X kan muligens/kanskje gi en reduksjon/økning i utfall Kunnskapsgrunnlaget antyder at X kan gi en reduksjon/økning i utfall |
|
Liten, men viktig effekt |
X kan muligens/kanskje redusere/øke utfall noe/litt Kunnskapsgrunnlaget antyder at X kan redusere/øke utfall noe/litt X kan muligens/kanskje gi en liten/svak reduksjon/økning i utfall Kunnskapsgrunnlaget antyder at X kan gi en liten/svak reduksjon/økning i utfall |
|
Liten og uvesentlig effekt eller ingen effekt |
X kan muligens/kanskje gi liten eller ingen forskjell i utfall Kunnskapsgrunnlaget antyder at X kan gi liten eller ingen forskjell i utfall X gir muligens/kanskje hverken reduksjon/økning eller [sett inn motstykke til reduksjon/økning] i utfall X reduserer/øker neppe utfall Kunnskapsgrunnlaget antyder at X muligens/kanskje ikke reduserer/øker utfall |
|
SVÆRT LAV tillit til kunnskapsgrunnlaget |
|
|
Uansett effekt |
Kunnskapsgrunnlaget om effekten av X på utfall er svært usikkert Kunnskapsgrunnlaget er svært usikkert når det gjelder effekten av X på utfall |
Bruk av data fra systematiske oversikter
I en systematisk oversikt er resultatene fra studiene allerede sammenfattet. Oppgaven til forskerne er da å vurdere og sammenfatte relevante data fra én eller flere systematiske oversikter i en «oversikt over oversikter» I dette er det flere utfordringer.
Ved inklusjon og gjennomgang av systematiske oversikter er det fire forhold som er avgjørende:
- Er den systematiske oversikten relevant for problemstillingen (vår PICO)?
- PICO er fullstendig overlappende
- PICO er delvis overlappende
- Er dette en systematisk oversikt av tilstrekkelig kvalitet (primært høy, ev. moderat) til at vi kan stole på resultatene (jfr. sjekkliste for systematiske oversikter)
- Vil resultatene være overførbare til vår setting (norsk helsetjeneste)?
- Er søket nytt nok til å vurderes som oppdatert? Eller trenger denne oversikten oppdatering for å være nyttig?
Ved gjennomgang av resultatene er det vår PICO som er førende for hvilke data som skal formidles fra den systematiske oversikten. Dersom det mangler data for enkelte endepunkter (for eksempel om sikkerhet), bør det spesifiseres.
Informasjon om de systematiske oversiktene presenteres i en tabell som viser karakteristika for inkluderte systematiske oversikter og kvalitetsvurdering. Resultatene presenteres i tekst og ved GRADE-tabeller (se neste kapittel).
Mer om sammenstilling av data fra systematiske oversikter i kapittel om sikkerhet og Cochrane Handbook, kapittel V (2).